Ever had an endless list of bacterial names that needed a trim?
Ever see a tree where the bacterium chosen is not the famous one, but it's cousin? Or actually a tree where you don't recognise a single name?
The issue of picking bacteria from a list is what I call Noah's ark dilemma. This term is used generally for the biblical problem of the size of the boat required for all the animals in existence (except dinosaurs). Here I mean it picking the most meaningful bacteria from a list. In the past year, I have come to rely on a simple solution: Pubmed popularity.
Showing posts with label Bacteria. Show all posts
Showing posts with label Bacteria. Show all posts
Tuesday, 11 April 2017
Tuesday, 23 August 2016
Methodological sabotage of growth rates
Following the interest in a previous post about analysing growth curves in Matlab I would like to discuss issues in growth curves that can arise from the methodological/biological side of things. Fitting the data is perfect if the data is perfect, if not, looking at what is wrong by eye is warranted for future corrections.
Growth curves can be divided into phases (lag, exponential, stationary and death) and each has its pitfalls.

Growth curves can be divided into phases (lag, exponential, stationary and death) and each has its pitfalls.

Sunday, 22 November 2015
Noah's ark dilemma in phylogeny
When looking at bacterial diversity, be it for a conserved gene or the organism itself, a common problem is the wealth of sister strains and sister species: this is a bother as often one would like a balanced representation. This leads to a Noah's ark dilemma of having to pick one.

Tuesday, 6 October 2015
PrettyFastaJS
I wrote a small script to allow one to easily and prettily embed both nucleic acid and protein FASTA sequences on a webpage (it guesses based on EFILPQ which are not degerate bases, but residues). It was a mix of "I need this" and "I want to play with colours". The latter was rather painful. But the result is a JS modified and CSS coloured fasta files.
The files can be found in my GitHub repository for PrettyFastaJS and so are the explanations of how to use it. As a demo, here are two curious sequences. Two consecutive genes in the same operon that encode each a full length glycine dehydrogenases, which in other species is a homodimer, which suggests this may be a cool heterodimer.
The files can be found in my GitHub repository for PrettyFastaJS and so are the explanations of how to use it. As a demo, here are two curious sequences. Two consecutive genes in the same operon that encode each a full length glycine dehydrogenases, which in other species is a homodimer, which suggests this may be a cool heterodimer.
>Gthg02641 Glycine dehydrogenase (EC 1.4.4.2) [Geobacillus thermoglucosidasius TM242]
MLKNWGIAMHKDQPLIFELSKPGRIGYSLPELDVPAVRVEEVVPADYIRTEEPELPEVSELDIMRHYTALSKRNHGVDSGFYPLGSCTMKYNPKINENVARLAGFAHIHPLQPEETVQGALELMYDLQEHLKEITGMDAVTLQPAAGAHGEWTGLMMIRAYHEANGDFQRTKVIVPDSAHGTNPASATVAGFETITVKSTEDGLVDLEDLKRVVGPDTAALMLTNPNTLGLFEENILEMAKIVHDAGGKLYYDGANLNAVLSKARPGDMGFDVVHLNLHKTFTGPHGGGGPGSGPVGVKADLIPFLPKPVVEKGENGYYLDDDRPQSIGRVKPFYGNFAINVRAYTYIRSMGPEGLKAVAEYAVLNANYMMRRLAEYYDLPYDRHCKHEFVLSGKRQKKLGVRTLDIAKRLLDFGFHPPTVYFPLIVEECMMIEPTETESKETLDAFIDAMIQIAKEAEENPEIVQEAPHTTVVKRLDETKAARKPILRYQKQ
>Gthg02642 Glycine dehydrogenase (EC 1.4.4.2) [Geobacillus thermoglucosidasius TM242]
MLHRYLPMTEEDKREMLNVIGVDSIDDLFADIPESVRFRGELNIKKAKSEVELWKELSALAAKNADVKKYTSFLGAGVYDHYIPAIVDHVISRSEFYTAYTPYQPEISQGELQAIFEFQTMICELTGMDVANSSMYDGGTALAEAMLLSAAHTKKKKVLLAKTVHPEYRGVVKTYAKGQRLHVVEIPFQHGVTDLEALKAEMDDEVACVIVQYPNFFGQIEPLKDIEPVAHSCKSMFVVASNPLALGILAPPGKFGADIVVGDVQPFGIPMQFGGPHCGYFAVKAELMRKIPGRLVGQTTDEEGRRGFVLTLQAREQHIRRDKATSNICSNQALNALAASVAMTALGKKGIKEMATMNIQKAQYAKNELVKHGFAVPFTGPFFNEFVVCLAKPVAEVNKQLLRKGIIGGYDVGRDYPELQNHMLIAVTELRTKEEIDMFVKELGDCHA
Wednesday, 6 May 2015
Speculations about methionine biosynthesis genes
Last year I wrote a review on the bacterial diversity methionine biosynthesis:
It was crammed with facts and a couple of deductions that in my opinion are correct. However, there were a lot of hypotheses and conjectures, from plausible to wild, that did not make it into paper. Here I thought I might mention a few.
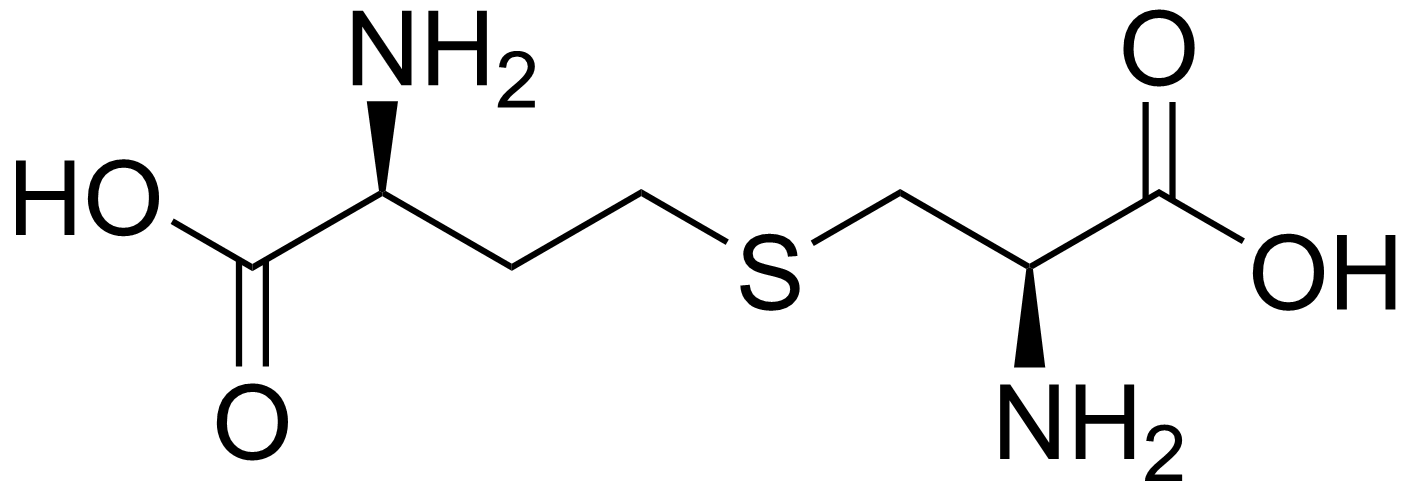 Cystathionine is a cysteine/alanine and a homocysteine/homoalanine joined together with a thioether. It has a short side (S is on the β) and a long side (S on the γ).
Cystathionine is a cysteine/alanine and a homocysteine/homoalanine joined together with a thioether. It has a short side (S is on the β) and a long side (S on the γ).
MetC is cysthationine β-lyase, it eliminates cystathionine at the thioether bond. On the shorter side (β).
MetB is cystathionine synthase it eliminates O-acetyl-homoserine at the ester bond and then attacks it with cysteine's thiol making cystathionine.
The two PLP enzymes hold cystathionine at some point but in radically different ways, one on the β side (MetC), the other on the γ (MetB).
Taking a step back, we have two types of cystathionine lyase and what controls the specificity between a β-lyase and a γ-lyase is not known —there have been a few papers looking into making MetC into a MetB and viceverse, but unfortunately nothing tackling this simpler issue. Cystathionine looks nearly identical from both sides: the sulfur bridge is hard to tell apart from a methyl group as there is only a slight size and charge difference. Methionine can be substituted with norleucine in protein with only minimal effect. Therefore it is intriguing how the enzymes bind it tightly in a specific way. My theory is that sulfur-π interactions may be involved as there are several tyrosines in the active site of MetC. Additionally, a β-elimination might be easier than a γ-elimination, therefore it is shame that there is a decent amount of data of the lack of γ-elimination activity in the β-lyase, but not viceversa. Therefore it would seem more likely to have a powerful bifunctional β- γ- cystathionine lyase than have retrained one that is strongly specific. However, this bifunctional enzyme is not an evolutionary a good idea due to the number of round trips it would do. Specifically, cysteine or homocysteine would go into making cystathionine, which the uncommitted lyase would either correctly transform or return a starting substrate —at the cost of ATP. The reason for this fascinating parenthesis is to conclude that cystathionine synthase/lyase combo that could do both, would be equally as bad of an idea —it would work due to flux from excess substrate to product in demand, but it is just extremely inefficient.
Ferla MP, Patrick WM. Bacterial methionine biosynthesis. Microbiology. 2014 Aug;160(Pt 8):1571-84.
PMID: 24939187, doi: 10.1099/mic.0.077826-0 and pdf.
PMID: 24939187, doi: 10.1099/mic.0.077826-0 and pdf.
The MetCombo
It is my opinion that a bifunctional enzyme that catalyses both the MetC and the MetB reaction is impossible. I have come to call this hypothetical enzyme, the MetCombo. So the data at hand are:- MetC and MetB are close homologues and it is really hard to tell them apart in a phylogram —with the bold assumption that the uncharacterised genes are what have been guess.
- Both KEGG and EcoCyc take the close homology to mean that bifunctional enzyme is present in several organisms —basically all those with MetB, which is a lot as you know from the met biosynthesis paper
- They are in the same pathway
- Nobody has ever seen a metCombo
- Papers that try to evolve MetC ↔ MetB are not realy successful
- Personal results: E. coli metC cannot rescue metB
- Personal results: Thermotoga maritima "metB" is actually a metC and it has no in vivo or in vivo MetB activity(check out my thesis)
- Catalytically a metC and metB in a single active site would be a disaster.
Catalytic profligacy
MetC is cysthationine β-lyase, it eliminates cystathionine at the thioether bond. On the shorter side (β).
MetB is cystathionine synthase it eliminates O-acetyl-homoserine at the ester bond and then attacks it with cysteine's thiol making cystathionine.
The two PLP enzymes hold cystathionine at some point but in radically different ways, one on the β side (MetC), the other on the γ (MetB).
Taking a step back, we have two types of cystathionine lyase and what controls the specificity between a β-lyase and a γ-lyase is not known —there have been a few papers looking into making MetC into a MetB and viceverse, but unfortunately nothing tackling this simpler issue. Cystathionine looks nearly identical from both sides: the sulfur bridge is hard to tell apart from a methyl group as there is only a slight size and charge difference. Methionine can be substituted with norleucine in protein with only minimal effect. Therefore it is intriguing how the enzymes bind it tightly in a specific way. My theory is that sulfur-π interactions may be involved as there are several tyrosines in the active site of MetC. Additionally, a β-elimination might be easier than a γ-elimination, therefore it is shame that there is a decent amount of data of the lack of γ-elimination activity in the β-lyase, but not viceversa. Therefore it would seem more likely to have a powerful bifunctional β- γ- cystathionine lyase than have retrained one that is strongly specific. However, this bifunctional enzyme is not an evolutionary a good idea due to the number of round trips it would do. Specifically, cysteine or homocysteine would go into making cystathionine, which the uncommitted lyase would either correctly transform or return a starting substrate —at the cost of ATP. The reason for this fascinating parenthesis is to conclude that cystathionine synthase/lyase combo that could do both, would be equally as bad of an idea —it would work due to flux from excess substrate to product in demand, but it is just extremely inefficient.
Conflicting results
Some methionine gene rescue experiments go in different ways that expected and there occasionally are concentration dependent oddities. My opinion is that this is due toone of the following:- It is dominating the threonine branch point and there is not enough threonine being produced.
- It is depleting all the cysteine or homocysteine
The ancestral PLP-dependent methionine gene
TBAMethionine and norleucine
TBAAlignment file
Here is the alignment file of manually aligned genes of various metB metC etc.Tuesday, 4 September 2012
Homologues and synonyms
All creatures great and small evolve, but evolution is not limited to the biological realm: languages evolve too and in a similar way.
My interest in languages stems from their ability to evolve with many similarities to enzyme evolution (and in light of not being able to spill the beans on my own research, I seem to post here a lot about words —And this is another!)
The technical words in linguistics differ from those in biology and I have yet to find an enlightening paper on the coevolution of synonyms and the parallels between language and genomes.
In enzymology, protein function and structure are not not always linked. Proteins with different functions can have similar structures having evolved from the same ancestral gene (functionally-divergent homologues) and proteins with different structures can perform the same function (functionally-convergent analogues).
In a language, words can have similar meanings, yet have different origins (synonyms) and words from the same origin can have different meanings.
New genes enter an organism via gene duplication, horizontal gene transfer or gene birth. Similarly, new words enter a language by duplication, loanwords (words of foreign origin) or onomatopoeiae.
English is a really great language for two reasons: it is my mother-tongue and it is a hybrid.
Regarding the latter reason, over a third of the words in the English dictionary were acquired from French due to the Norman invasion of 1066. The grammar and basic vocabulary remained that of Old English, whereas the advanced vocabulary was that of Old French.
A parallel to this can be drawn with the weird and wonderful bacterium Thermotoga maritima, 24% of whose genome is of archaeal origin: the replication and expression machinery is bacterial, but several metabolic routes are archaeal.
A loanword is a foreign word that is adopted in a language thanks to its real or percieved utility, whereas a horizontal gene transfer is an aquisition of a foreign gene in a genome thanks to its fitness benefits. The original spelling of loanwords are gradually lost in favour of a more compatible spelling and similarly the codon and amino acid compositions of trasferred genes also gradually change to match that of the new genome.
Often synomyms of different origins coexist, in English for a while the Old-Norse–originating window (vinauga, wind+eye), the Old-English–originating eagþyrl (eye+hole) and the Old-French–originating fenestre were coexisting, until one won. When French entered into the English language many synonyms died, but many survived in a figurative meaning, for example, enthrall litterally means to enslave, but nowadays it is used figurately, ie. capuring one's attention.
With genes the pressure to remove genes with identical function (be they paralogues, xenologues or analogues) depends on the selective pressure and in Eukaryotes they can coexist for some time.
Some words adopt alternative spellings, which can dissapear or gain different functions, such as the pairs yet and get, passed and past, and especial and special. Gene duplication does the same. In the IAD model of gene divergence, the new function comes before the amplification.
English, French and several other languages use the Latin alphabet to write words down. However, the phonetics of Latin lacks several sounds present in these and work-arounds are done. The letter h is used as a modified in English to make wh, th and ch sounds and vowel combinations allow extra vowel sounds. Old English used to be written with Anglo-saxon runes and then, with Christianity, switched over to the Latin one, bringing with it two heavily used runic letters absent in the Latin alphabet (þ and ƿ). However, as most typesetting letters were produced in France the letters died out. Despite the obvious simplicity they endow, new letters are very rarely added.
The work-around the lack of letters results in coding problems: the th group in Bath, Chatham Islands and Thailand differ, as the former is the fricative, the second is a word fusion (the H is not a modifier) and the latter is a plosive (a “violent” T). The only way to know is to know the exceptions or guess from the etymology, which can be misleading in thyme and Thames.
In protein several non-standard residues can be found. None of these use a recoded codon by itself, but require special sequences or post-transcriptional modifications, so the system differs slightly in that new letters (codons) cannot be added, but is similar in its workarounds.
Many differences exist, however.
Languages have grammar and generally authoritative bodies acting independantly of the evolution of the language (French academy).
Many suffices and prefices are highly constructive, a modularity that is hard to find in genes.
Enzymes have promiscuous function, minor non-physiological functions that can lead to new main activities: a property that is different in words. Words have multiple definitions and some are often confused. The word brothel used to mean prostitute, but it was confused with the word bordel and the meaning of the latter was bestowed on the former. Biannual traditionally means two-yearly, but its continual misuse as semestral means that the word has two discordant definitions, annulling its functionality. Genes have layers of regulation, whereas words don't. However, the metaphor could be stretch to equate grammar to regulation, but that may be wholly in the handwaving realm…
My interest in languages stems from their ability to evolve with many similarities to enzyme evolution (and in light of not being able to spill the beans on my own research, I seem to post here a lot about words —And this is another!)
The technical words in linguistics differ from those in biology and I have yet to find an enlightening paper on the coevolution of synonyms and the parallels between language and genomes.
In enzymology, protein function and structure are not not always linked. Proteins with different functions can have similar structures having evolved from the same ancestral gene (functionally-divergent homologues) and proteins with different structures can perform the same function (functionally-convergent analogues).
In a language, words can have similar meanings, yet have different origins (synonyms) and words from the same origin can have different meanings.
New genes enter an organism via gene duplication, horizontal gene transfer or gene birth. Similarly, new words enter a language by duplication, loanwords (words of foreign origin) or onomatopoeiae.
English is a really great language for two reasons: it is my mother-tongue and it is a hybrid.
Regarding the latter reason, over a third of the words in the English dictionary were acquired from French due to the Norman invasion of 1066. The grammar and basic vocabulary remained that of Old English, whereas the advanced vocabulary was that of Old French.
A parallel to this can be drawn with the weird and wonderful bacterium Thermotoga maritima, 24% of whose genome is of archaeal origin: the replication and expression machinery is bacterial, but several metabolic routes are archaeal.
A loanword is a foreign word that is adopted in a language thanks to its real or percieved utility, whereas a horizontal gene transfer is an aquisition of a foreign gene in a genome thanks to its fitness benefits. The original spelling of loanwords are gradually lost in favour of a more compatible spelling and similarly the codon and amino acid compositions of trasferred genes also gradually change to match that of the new genome.
Often synomyms of different origins coexist, in English for a while the Old-Norse–originating window (vinauga, wind+eye), the Old-English–originating eagþyrl (eye+hole) and the Old-French–originating fenestre were coexisting, until one won. When French entered into the English language many synonyms died, but many survived in a figurative meaning, for example, enthrall litterally means to enslave, but nowadays it is used figurately, ie. capuring one's attention.
With genes the pressure to remove genes with identical function (be they paralogues, xenologues or analogues) depends on the selective pressure and in Eukaryotes they can coexist for some time.
Some words adopt alternative spellings, which can dissapear or gain different functions, such as the pairs yet and get, passed and past, and especial and special. Gene duplication does the same. In the IAD model of gene divergence, the new function comes before the amplification.
English, French and several other languages use the Latin alphabet to write words down. However, the phonetics of Latin lacks several sounds present in these and work-arounds are done. The letter h is used as a modified in English to make wh, th and ch sounds and vowel combinations allow extra vowel sounds. Old English used to be written with Anglo-saxon runes and then, with Christianity, switched over to the Latin one, bringing with it two heavily used runic letters absent in the Latin alphabet (þ and ƿ). However, as most typesetting letters were produced in France the letters died out. Despite the obvious simplicity they endow, new letters are very rarely added.
The work-around the lack of letters results in coding problems: the th group in Bath, Chatham Islands and Thailand differ, as the former is the fricative, the second is a word fusion (the H is not a modifier) and the latter is a plosive (a “violent” T). The only way to know is to know the exceptions or guess from the etymology, which can be misleading in thyme and Thames.
In protein several non-standard residues can be found. None of these use a recoded codon by itself, but require special sequences or post-transcriptional modifications, so the system differs slightly in that new letters (codons) cannot be added, but is similar in its workarounds.
Many differences exist, however.
Languages have grammar and generally authoritative bodies acting independantly of the evolution of the language (French academy).
Many suffices and prefices are highly constructive, a modularity that is hard to find in genes.
Enzymes have promiscuous function, minor non-physiological functions that can lead to new main activities: a property that is different in words. Words have multiple definitions and some are often confused. The word brothel used to mean prostitute, but it was confused with the word bordel and the meaning of the latter was bestowed on the former. Biannual traditionally means two-yearly, but its continual misuse as semestral means that the word has two discordant definitions, annulling its functionality. Genes have layers of regulation, whereas words don't. However, the metaphor could be stretch to equate grammar to regulation, but that may be wholly in the handwaving realm…
Subscribe to:
Posts (Atom)